Test analytics for
GitHub and GitLab
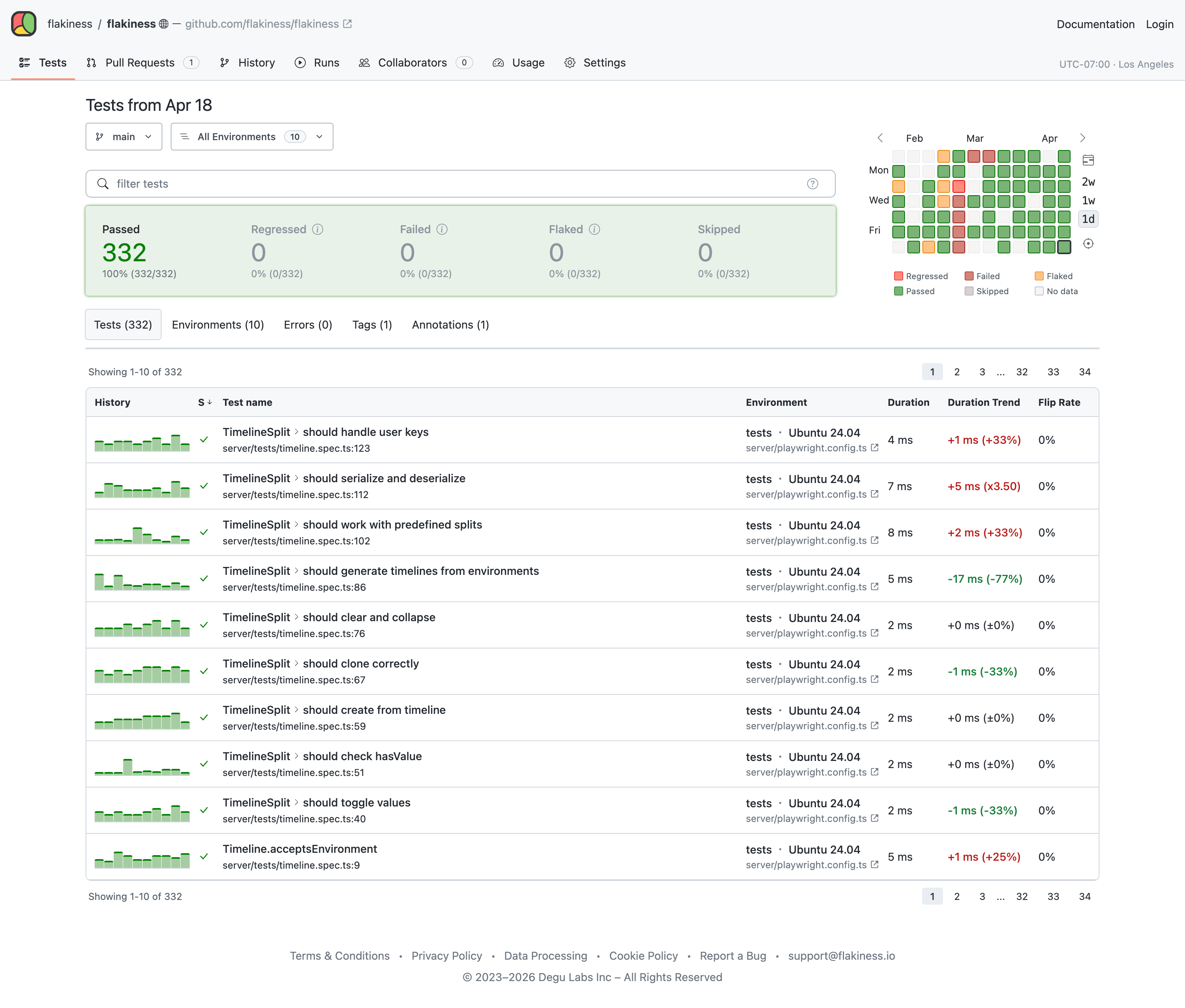
Track each test's performance across commits to detect regressions.
Separate regressions from flakes
Every result is tied to the commit and environment it ran on. Flakiness.io can tell whether a failure is new in the PR, already broken on main, or flipping on the same commit. Never land a regression again.
Any test, any runner
Frontend in Vitest. E2E in Playwright. Backend in Pytest or JUnit.
Flakiness.io gathers all tests in one place, with high-quality reporters for the major runners, a JUnit XML bridge for everything else, and a Node.js SDK for custom integrations.








Faster CI from balanced shards
A sharded run is only as fast as its slowest shard. Splitting tests by count leaves some shards overloaded and others idle, so the whole run waits on a straggler.
Flakiness.io records how long every test takes, and compatible test runners can use that information to balance shards by real duration.
Any CI, one report
Works with any CI provider. Flakiness.io ingests results as they land, automatically merges shards, and keeps staging and production histories separate.
Zoom in, Zoom out
Test reports range from a week-level overview across every environment down to a single test in a single run.
Slice results with the Flakiness Query Language, group failures into error bins, and read system telemetry alongside the test waterfall.
Keep evidence attached
Logs, screenshots, videos and traces upload alongside every report. Powerful built-in viewers handle image diffing and Playwright traces in the browser.
Configurable data retention lets you keep what matters and prune the rest.
See a report with attachmentsRepository-native access
Flakiness.io follows your GitHub or GitLab repository permissions. People with access to a connected repository can see its test analytics; people without access can't.
You do not need to recreate users, teams, permissions, or single sign-on (SSO) inside Flakiness.io. Access stays where your engineering team already manages it: GitHub or GitLab.
Compact context for coding agents
Raw CI output is expensive context for coding agents. Flakiness.io turns a failed run into a compact record: what failed, whether it regressed, how it behaved on main, and which logs and artifacts matter.
Agents spend fewer tokens gathering context and less time fixing problems.
 Claude Code
Claude Code Codex
Codex Cursor
CursorWe charge for storage,
not tests or seats
Most platforms charge per test run, per dashboard user, or both. Flakiness.io charges for stored data. Run more tests and let everyone with repository access view the results — without per-run or per-seat fees.
Choose your plan
Starts free — no credit card required.
Free
- Core test analytics
- 1 GB artifacts storage
- 90 days data retention
- Unlimited test runs
- Unlimited users
- Public projects
- Private projects
- Slack Notifications
- Self-hosting
- Audit log
- Standard support
Startup
- Core test analytics
- 10 GB artifacts storage
- 180 days data retention
- Unlimited test runs
- Unlimited users
- Public projects
- Private projects
- Slack Notifications
- Self-hosting
- Audit log
- Standard support
Growth
- Core test analytics
- 100 GB artifacts storage
- 365 days data retention
- Unlimited test runs
- Unlimited users
- Public projects
- Private projects
- Slack Notifications
- Self-hosting
- Audit log
- Priority support
Enterprise
- Core test analytics
- Custom artifacts storage
- Custom data retention
- Unlimited test runs
- Unlimited users
- Public projects
- Private projects
- Slack Notifications
- Self-hosting
- Audit log
- Priority support
Frequently asked questions
Why is Flakiness.io cheaper than other platforms?
Flakiness.io charges for stored data, not per user or test run. The analytics engine is built on interval unions, which keeps large test histories efficient to pack and process at scale. Pricing follows that architecture: storage drives cost, not execution count.
How does Flakiness.io detect flakiness?
Every test result is tied to the commit and environment it ran on. A test that flips between pass and fail on the same commit is classified as a flake; a test whose outcome changes at a specific commit and stays that way is a regression. This separates noise from real breakage without rerunning anything.
The commit-aware analysis behind this is grounded in research published by Apple engineers.
Can Flakiness.io handle our massive monorepo?
Yes. Flakiness.io is built for large test histories, mixed stacks, and high test volume. We have tested the system on established projects with 500,000+ tests, and it handled the volume without issue.
Can I host Flakiness.io on my own servers?
Yes. A self-hosted deployment is one application container backed by PostgreSQL and an S3-compatible object store. The reporters and the Flakiness CLI work with custom deployments. See the self-hosting docs or contact [email protected] for licensing.
Who develops the test runner integrations?
The Flakiness JSON Report format is open source, so anyone can build a reporter.
The Flakiness.io team maintains the official reporters for the major test runners, the JUnit bridge, and the platform itself. See the test runners documentation for the full list.
More questions? Reach out at [email protected]
Who's behind Flakiness.io
A decade of building dev tools

Flakiness.io is created by Andrey Lushnikov, who spent over a decade at Google and Microsoft building the tools that testing engineers rely on every day: creating Google Puppeteer and co-founding Microsoft Playwright.